LTX-2 & Multi-Input
Video
Fast latent video generation using a 3-stage temporal process. The multi-input variant supports custom VSE LoRAs and detail passes.
Weights: Hugging Face
HuggingFace →
Wan T2V / I2V
Video
Generates fluid sequences with strong physics adherence and temporal rendering characteristics. High motion range accuracy.
Weights: Wan-AI
HuggingFace →
SkyReels V1 (Hunyuan)
Video
Text-to-video and image-to-video models leveraging Hunyuan DiT. Features a compressed INT4 architecture option for reduced memory allocation.
Weights: Skywork
HuggingFace →
MiniMax Cloud Engine
Video
Alternative API-steered generation system for rapid draft generation. Requires setting an active personal key.
Provider: MiniMax API
minimaxi.com →
FLUX.2 Dev (4-Bit Quantized)
Image
Optimized text-to-image pipeline for detailed layouts, graphics, and high-fidelity prompt compliance. Fits within 6 GB limits.
Weights: Hugging Face (BnB)
HuggingFace →
FLUX.2 Klein (4B & 9B)
Image
Lightweight parameter modifications. Intended for fast layout previews and efficient tile upscaling.
Weights: Black Forest Labs
HuggingFace →
FLUX Kontext & Relighting
Image
Performs instruction-based changes on loaded image strips. Allows you to re-light or edit specific areas without manual masking.
Weights: Kontext Community
HuggingFace →
OmniGen V1
Image
A unified multi-image model for image editing, generation, and multi-reference image composition.
Weights: Shitao
HuggingFace →
Lumina Image 2.0
Image
Advanced diffusion transformer model designed to process high-density visual details and complex layout conditions.
Weights: Alpha-VLLM
HuggingFace →
BiRefNet-HR
Image
High-resolution automated background extraction engine. Isolates subjects directly on VSE layers for fast compositing.
Weights: ZhengPeng7
HuggingFace →
Chatterbox & Turbo
Audio
Clones voice performance details directly from short local reference files. Handles dialogue generation and long formats without processing lag.
Source: Resemble AI
GitHub →
MMAudio Sync Sound
Audio
Calculates synchronization coordinates directly from timeline video tracks to generate synchronized sound effects and foley tracks.
Weights: HK Cheng Rex
HuggingFace →
Foundation Music 1
Audio
Generates stereo musical stems and arrangements directly from text directions, BPM cues, and scale settings.
Weights: tin2tin Diffusers
HuggingFace →
ACE Step Audio
Audio
Flexible text-to-audio engine designed for sound design, ambient environments, and structural track sound effects.
Source: ACE-Step Team
GitHub →
Florence-2 Captioning
Text
Analyzes frame layers on the timeline to generate accurate captions, object coordinates, and tracking labels.
Weights: Microsoft
HuggingFace →
MoviiGen Prompt Engine
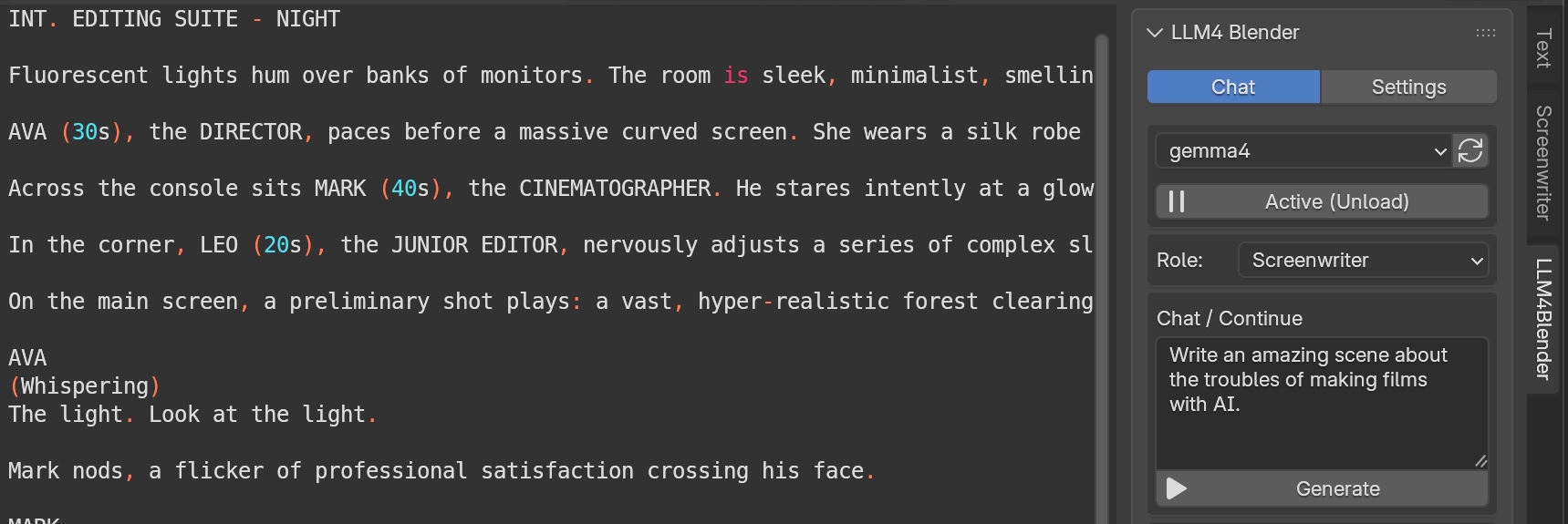
Text
Rewrites simple text inputs into rich, descriptive prompts structured for the temporal constraints of video models.
Weights: ZuluVision
HuggingFace →
Marlin Video Captions
Text
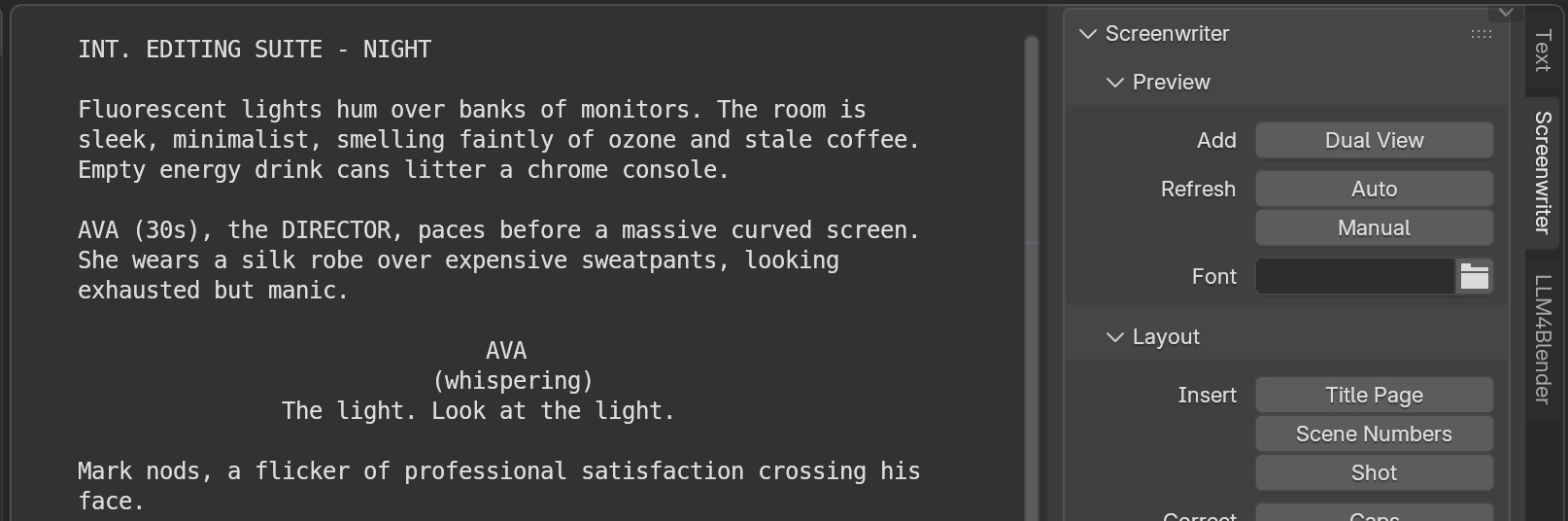
Generates narrative descriptions of motion and visual sequences from video strips, aiding the screenwriter layout.
Weights: Lunar Labs
HuggingFace →